
O buscador de internet Archie de 1990
Em 10 de setembro de 1990, o cientista da computação Alan Emtage lançava o sistema Archie, o motor de busca de Internet antes dos motores de busca da Internet.
Considerado o primeiro motor de busca da história da internet, o sistema Archie, criado por Alan Emtage (então estudante de computação da Universidade McGill, em Montreal/Canadá), nasceu da necessidade de poder encontrar mais rapidamente arquivos disponíveis em servidores públicos do tipo FTP (File Transfer Protocol) espalhados pela Internet.
Isso porque, naquela época, a grande rede, ainda um emaranhado de computadores de universidades e centros de pesquisa, dava seus primeiros passos de popularização e organização, com cada usuário precisando saber, de antemão, o endereço exato do servidor e o nome do arquivo que desejava acessar, inexistindo quaisquer ferramentas de “busca” como conhecemos hoje na Web.
Era como tentar encontrar um livro em uma biblioteca gigantesca, mas sem o auxílio de um catálogo. Era aí que o Archie entrava, oferecendo uma forma de automatizar esse processo de busca de arquivos ao disponibilizar um índice pesquisável que facilitava o acesso às informações espalhadas.
Batizado não como uma referência ao personagem de quadrinhos homônimo, mas representando uma abreviação (removendo o “v”) da palavra “archives” (arquivos, em inglês), o programa funcionava de maneira relativamente simples, conectando-se periodicamente aos servidores FTP públicos, coletando suas listas de arquivos e armazenando os dados obtidos em um banco de dados pesquisável, eliminando a necessidade do usuário ter que pular de servidor em servidor. 😊
Diferente dos mecanismos de busca atuais, o Archie não catalogava o conteúdo dos arquivos em si, mas apenas seus nomes e locais, obrigando o usuário a, ao menos, ter uma “noção” do nome do arquivo que buscava, o que já era suficiente para que estudantes e pesquisadores economizassem um enorme tempo na procura por softwares, documentos e bases de dados disponíveis online.
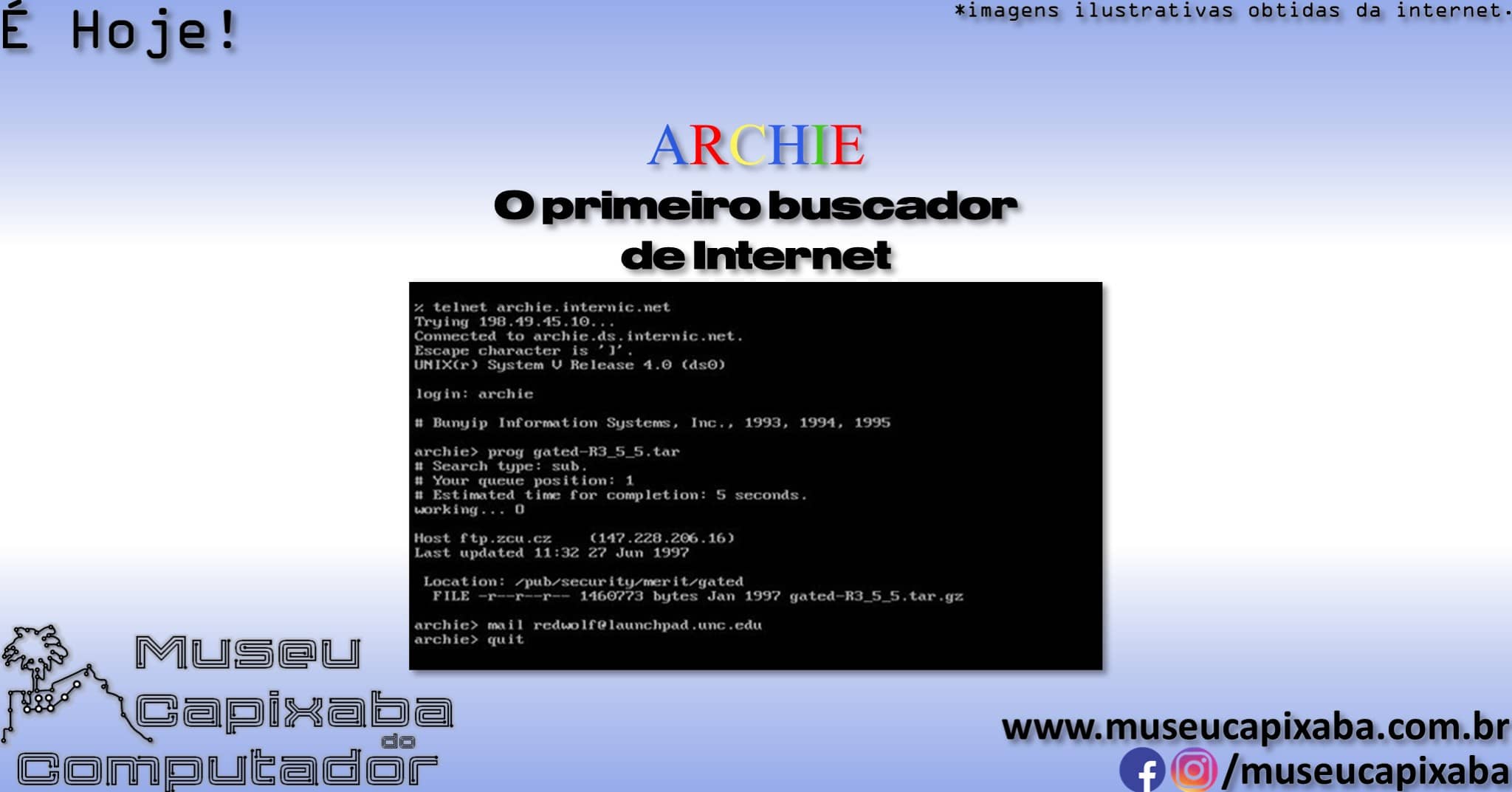
Tecnicamente, o Archie era um programa escrito em linguagem C, que rodava em um servidor UNIX. Ele não possuía uma interface gráfica como as que estamos acostumados atualmente, com os usuários acessando o servidor “archie.mcgill.ca” por meio do Telnet, um protocolo que permitia ao usuário se conectar a um computador remoto e operá-lo como se estivesse na frente dele.
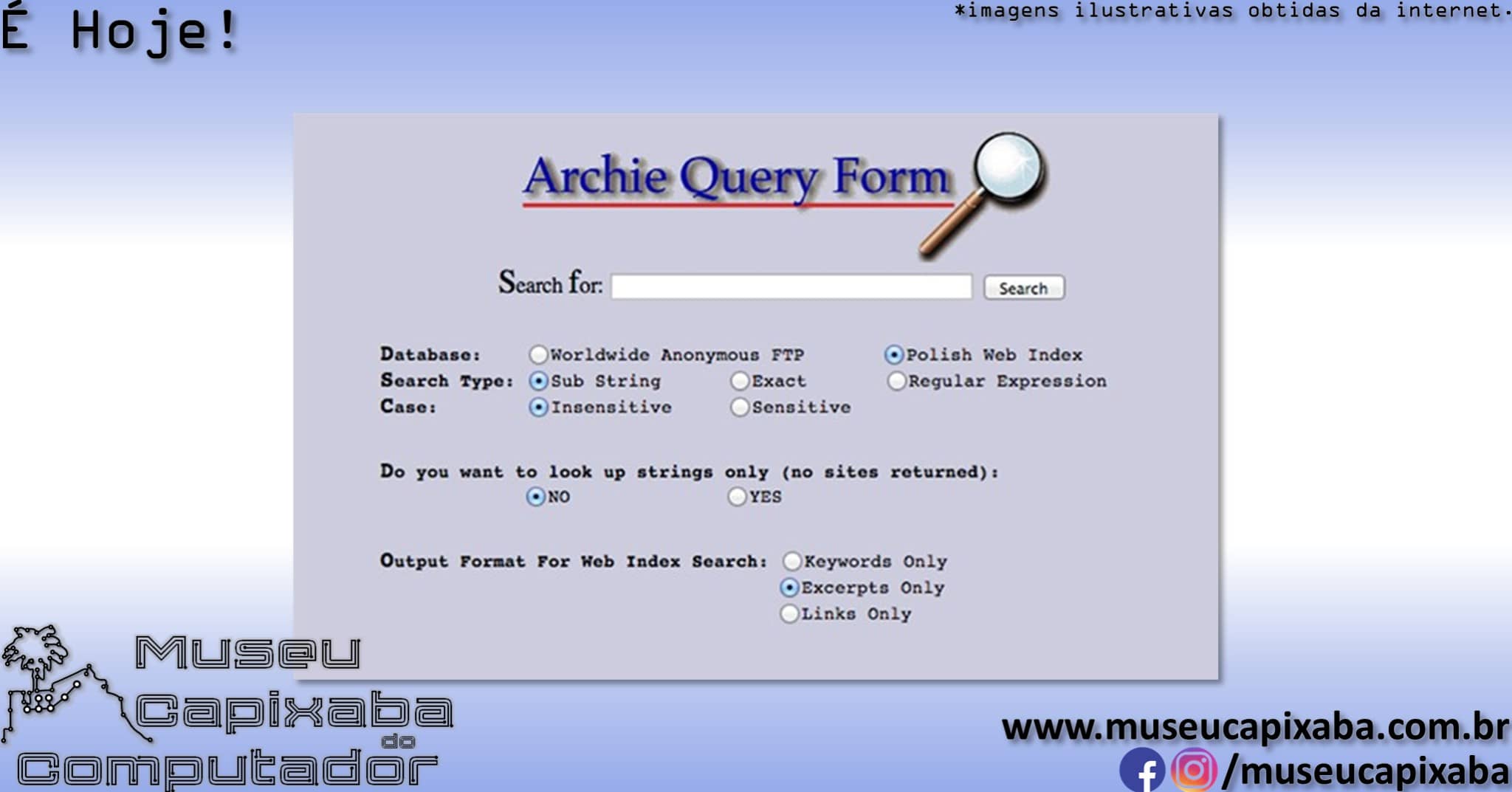
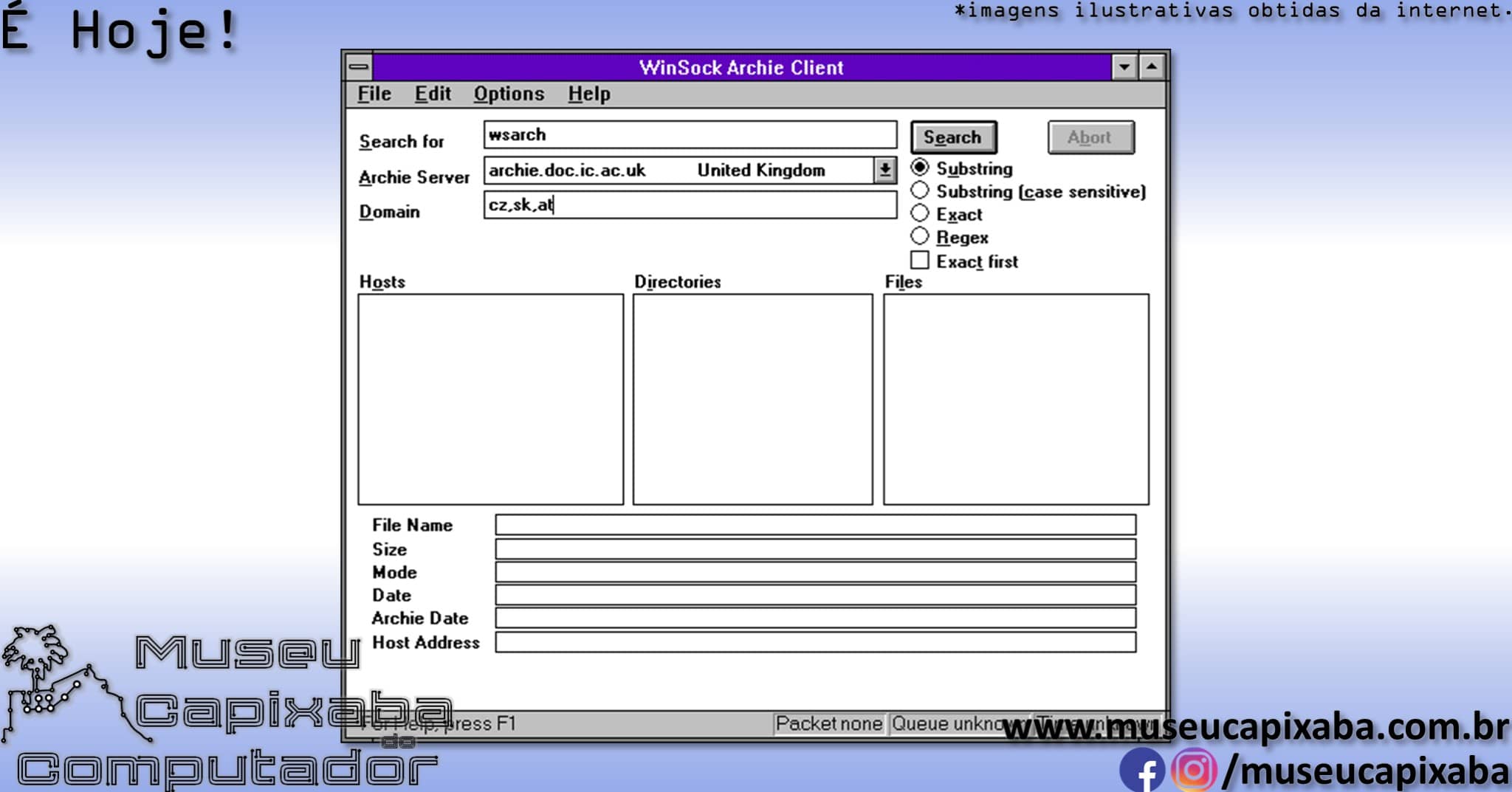
Uma vez conectados ao sistema, os usuários digitavam as palavras-chave desejadas, recebendo como resposta uma lista de endereços FTP onde os arquivos podiam ser encontrados. Posteriormente estas consultas passariam também a poder ser realizadas por e-mail, utilizando software cliente específico ou ainda por uma interface Web.
Embora rudimentar para os padrões atuais, essa inovação abriu caminho para o novo conceito de indexar informações disponíveis na rede para facilitar o acesso dos usuários, de forma que podemos dizer que, sem o Archie, talvez não tivéssemos hoje gigantes como Google, Baidu ou Bing, que herdaram e expandiram essa mesma lógica em escalas muito maiores.
O estrondoso sucesso do Archie rapidamente ultrapassaria os muros da Universidade McGil com outras instituições acadêmicas passando a utilizá-lo, fato que promoveria a criação de servidores adicionais em diferentes partes do mundo para dar conta da crescente demanda. Em seu auge, chegaria a receber mais de 50mil consultas por dia, representando 50% de todo o tráfego de internet da cidade de Montreal. 😊
Acompanhando a rápida evolução da rede mundial, em 1992, Alan Emtage fundaria, junto com Peter Deutsch e Bill Heelan, a empresa Bunyip Information Systems, com o objetivo de transformar o Archie em um serviço comercial, o que faria delas uma das primeiras (senão a primeira) empresas dedicadas a serviços de internet.
Mas o surgimento de protocolos com o Gopher e o HTTP em 1991, baseados no conceito de hipertexto, transferiria o foco dos arquivos de FTP para as páginas de conteúdo. O crescimento explosivo da World Wide Web a partir de 1993, especialmente após o surgimento de navegadores gráficos como o NCSA Mosaic, mudaria a forma com que as pessoas buscavam informações radicalmente, exigindo ferramentas mais sofisticadas.

Novos buscadores, como o Veronica (1992) e o Jughead (1993), surgiriam para indexar menus do Gopher, e posteriormente, o W3Catalog (1993), Wandex (1993), Aliweb (1993), JumpStation (1993) e o WebCrawler (1994) se tornariam os primeiros a indexar o conteúdo real das páginas web.
Assim, não conseguindo acompanhar a complexidade e a velocidade da nova “web”, o pioneiro e revolucionário Archie, ainda amarrado ao mundo do FTP, tornar-se-ia em pouco tempo obsoleto. Também a popularização de serviços comerciais como Yahoo!, Lycos e, mais tarde, Google, acabariam por marcar definitivamente o fim de sua relevância.
Contudo, o desenvolvimento ativo do Archie continuaria até 1996, quando sua última versão estável, a Archie 3.5, seria lançada. Servidores Archie ainda permaneceriam alguns anos em operação, tendo sido aposentados na virada do milênio, encerrando sua histórica jornada.
Em 2024, num extraordinário e extenso trabalho de pesquisa “arqueológica”, o canal YouTube “The Serial Port” encontrou aquela que seria a última ainda cópia existente deste revolucionário software, disponibilizada aqui neste endereço. Esta jornada foi documentada por eles no vídeo na seção abaixo.
E você, qual foi o primeiro mecanismo de busca que se recorda de ter utilizado?
Clique aqui e deixe seu comentário no final desta postagem! Sua participação é muito importante pra nós!
Vídeo(s):
*legendas disponíveis nos controles do Youtube, na opção “⚙ >> Legendas/CC >> Traduzir automaticamente”.
Mais em:
- O protocolo FTP de 1971
- O artigo “Gerenciamento de Informações: Uma Proposta” de 1989
- O primeiro servidor de páginas web de 1991
- A primeira página WEB da história de 1991
- O livro A Linguagem de Programação C de 1978
- O sistema operacional UNIX de 1971
- O navegador NCSA Mosaic de 1993
- O W3Catalog de 1993
- A criação do domínio Yahoo.com em 1995
- A fundação do Google em 1998
*As imagens utilizadas nesta postagem são meramente ilustrativas e foram obtidas da internet.
Quer nos ajudar com doações de itens para o acervo do Museu Capixaba do Computador – MCC?
Entre em contato conosco por meio dos canais de comunicação identificados nos ícones abaixo, ou ainda por quaisquer uma das nossas redes sociais listadas no topo da página.
 |  |
As doações também poderão ser entregues diretamente na sede do museu, neste endereço.
Para refrescar a memória e te ajudar a identificar alguns itens que buscamos, aqui você encontra nosso álbum de “Procura-se” .
Colabore você também com o primeiro museu capixaba dedicado à memória da tecnologia da informação!
Doe seus itens sem uso. Você ajuda a natureza e dá uma finalidade socialmente útil pra eles!










A Internet Engineering Task Force IETF de 1986